














Data
Understanding the strengths and limitations of the data used in scores is crucial to robust risk management.

Matching and confidence
Our service is based on data: we have some of the brightest data scientists and data engineers around and they are focussed on curating and matching data to allow our clients the best insight into the risks they manage.
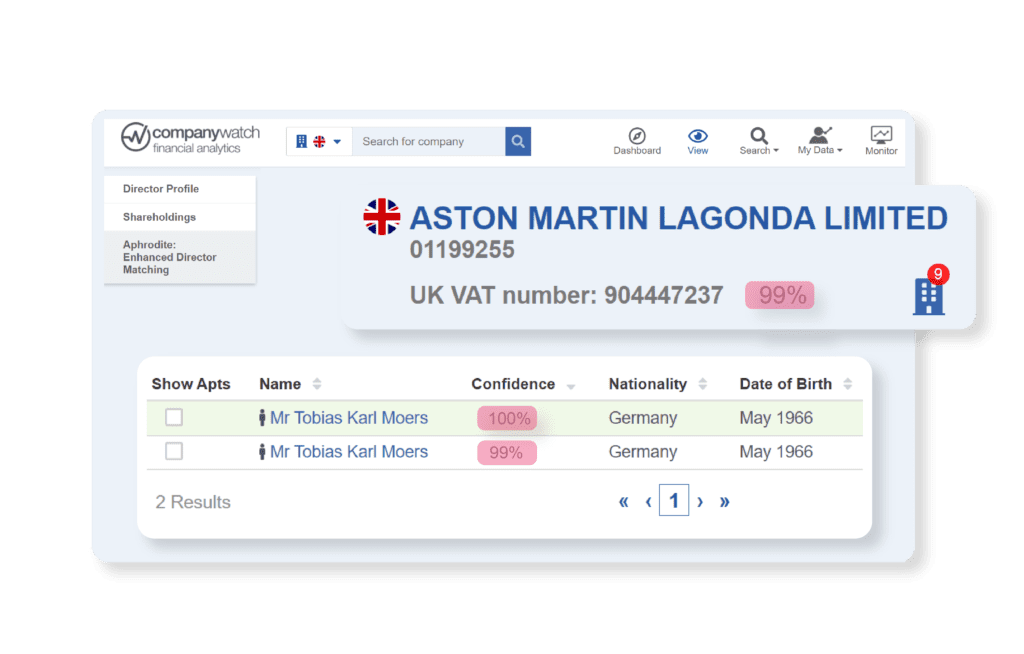
Data is drawn from public sources – but not all our sources use the Company Registration Number as a unique identifier. In the absence of unique identifiers, we have invested significant time building in-house matching algorithms to ensure we can link data sets.
We are transparent
Wherever possible we are transparent when we have to intervene to use a data matching process, such as VAT registration number match, Furlough data and Aphrodite®. In this case, we display a % confidence that it is a match.
Our Service
We help our clients manage their strategic business relationships, giving them scores that look at a medium-term forecast, and the tools to allow them to look even further into the future.

Explainable
We provide ‘white box’ scores, which allow you to make evidence-based decisions and justify these to key stakeholders in your organisation.

Interactive
Being able to model scenarios and understand ever-changing risk has never been more important. We give you the tools to do that.

Time-Saving
With tools like Aphrodite®, SearCHeD, TextScore® and our Furlough data matching, we allow you to investigate risks thoroughly in minutes.